

The entire project is divided into three phases:
1. Design autonomous path planning strategies, use LiDAR to complete map reconstruction for a 5m x 5m obstacle area;
2. Use AMCL for global positioning and path planning, use OpenCV to identify and classify images at multiple targets;
3. Design multimodal emotional feedback, give "emotion" to the robot.
TurtleBot2 Hardware Platform
A controller that fuses a Artificial Potential Field (attractive/repulsive forces from laser data) with a “memory” grid that down-weights already-scanned cells was designed. The memory grid was built based on robot's odometry sensor and the lidar scanning.
This hybrid APF + exploration weight steers the robot toward open, unseen space. Reactive modules (bumper recovery, corner-evasion, periodic 360° scans, and randomized yaw kicks) handle collisions and local minima.
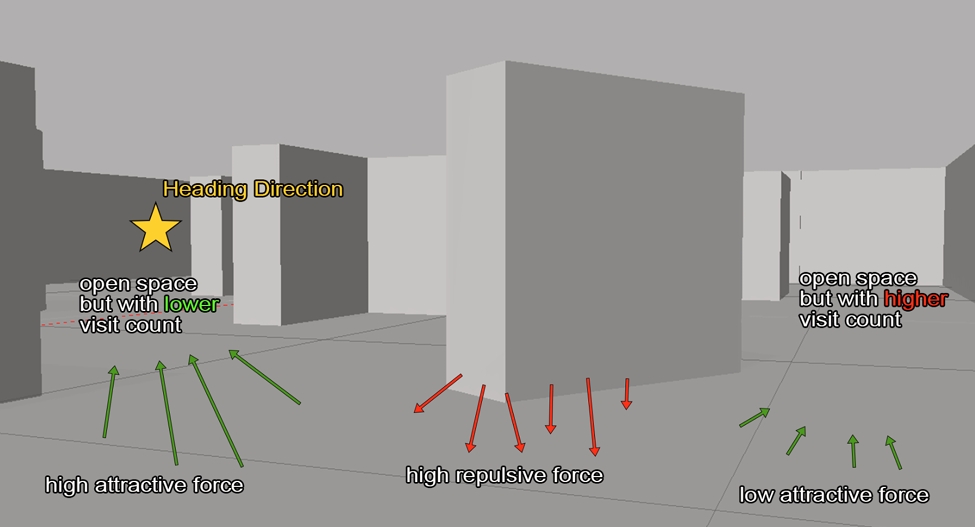
APF + Memory mechanism demo. (in Gazebo scene, first-person-view of the robot)
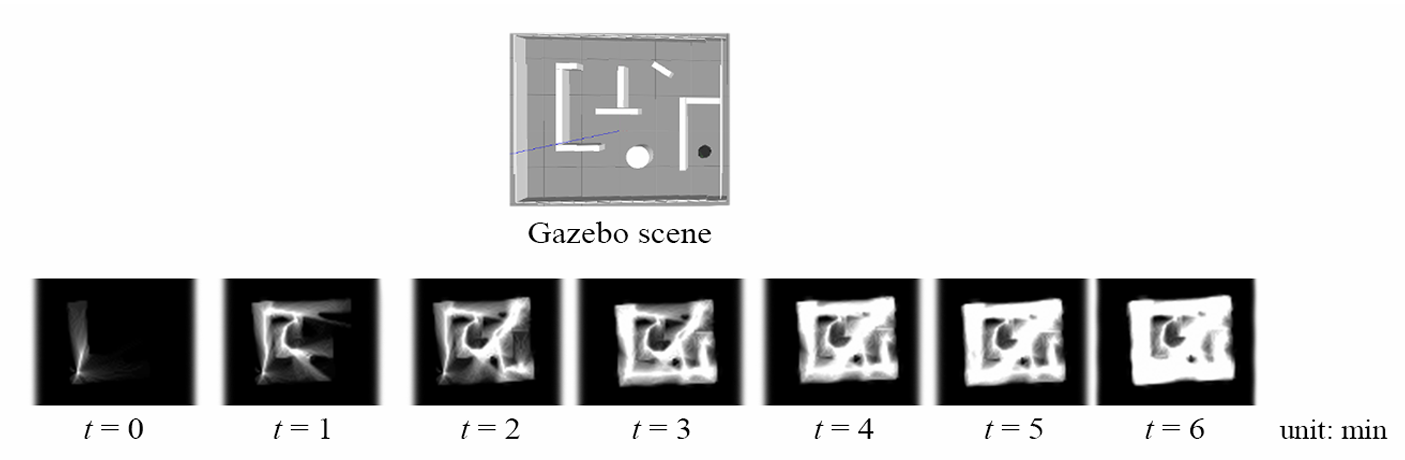
The memory grid iterations (brighter region: higher memory level, lower attraction)
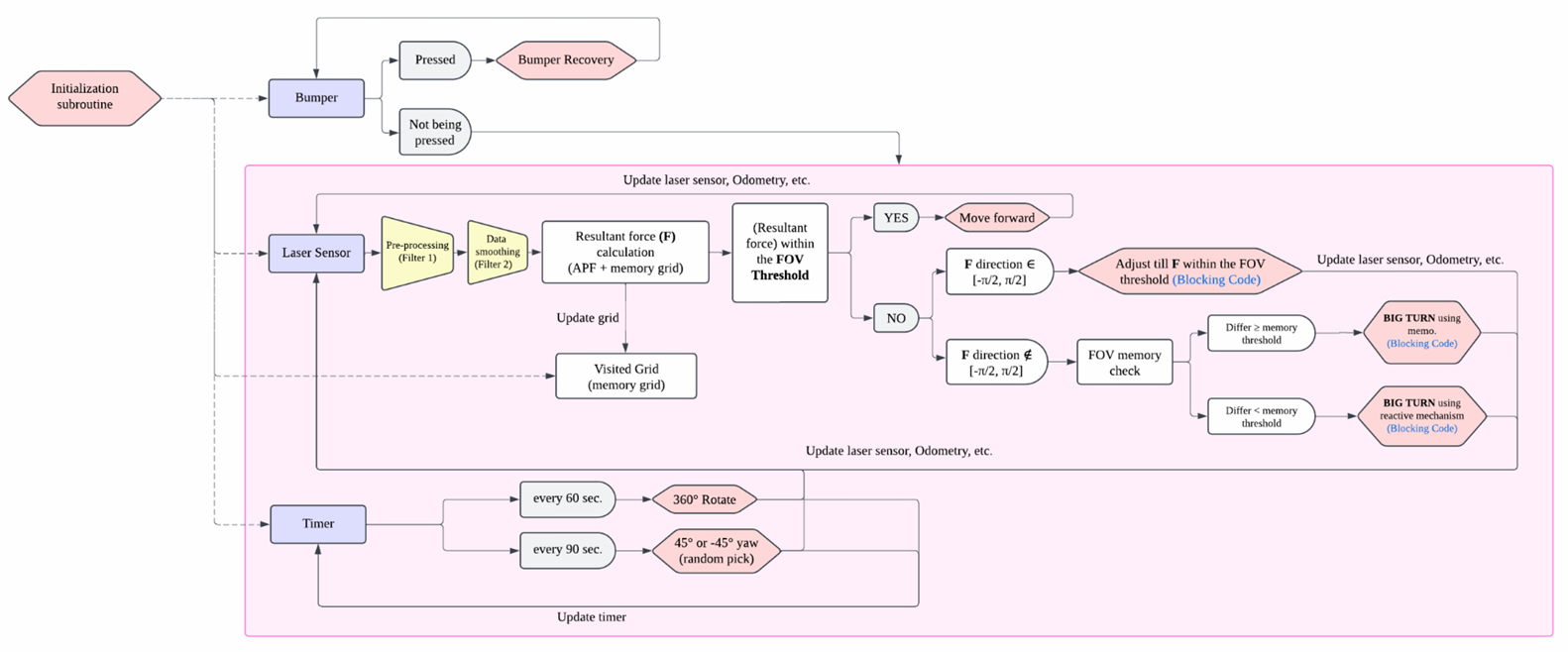
Low-level system diagram
Gazebo simulations and the real-world test showed fast, low-redundancy coverage; the robot systematically mapped the arena within the time limit while recovering from walls, corners, and dead-ends.

We built a two-layer stack that lets the bot autonomously tour five pre-plotted cereal-box posters, identify which of three template logos appears on each poster, and return home in under five minutes.
Navigation: A brute-force travelling-salesman search chooses the shortest order to visit the five goals. During driving, AMCL supplies pose estimates, and the DWA local planner converts it into collision-free velocity commands.
Vision: At each stop the RGB camera frame is turned to gray; SURF extracts scale- and rotation-invariant key-points, FLANN k-NN matching scores the scene against each template. A “sanity-check” routine re-scans if the initial results do not yield exactly three template IDs, one duplicate and one blank.
Using a depth-camera follower plus a designed finite-state machine, the robot can shift among six emotions—disgust, surprise, rage, happiness, discontent, and sadness—each conveyed with choreographed spins, shakes, and voice clips.